Introduction
Thanks to OpenAI.
Just around the release of GPT-5.5, Claude has acknowledged:
Model performance issues are real, and all usage quotas have been reset.
After a month of denial, the performance drop bug has finally been admitted by Anthropic:
- Inference level was secretly downgraded from “high” to “medium”
- A caching bug caused the conversation history to be cleared with each round
- A 25-word limit on prompts severely impacted output quality
These three bugs combined have led to a significantly degraded experience with Claude.
Fortunately, competitors have applied pressure, reminding users that relying solely on one model is unwise.
However, acknowledging bugs is a positive step. The timing is rather coincidental, with GPT-5.5 just released and Claude beginning to admit faults.
Could it be that GPT-5.5 helped debug Claude?
Dario, are you really intentionally making Claude less capable just to create a contrast with GPT-5.5?
Confirmed Bugs
To clarify, this is not the first time such issues have arisen.
Back in August last year, Anthropic had a similar postmortem regarding Opus 4.0 and 4.1, claiming, “We never intended to lower model quality.”
The new postmortem is titled “A postmortem of three recent issues.” The term “recent” is quite clear.
It’s not just a recent occurrence; the community has been voicing concerns for quite some time.
Over ten days ago, AMD AI’s senior director Stella Laurenzo released a detailed audit report covering 6,852 conversation files, 17,871 thought blocks, and over 230,000 tool calls.

The analysis revealed a dramatic drop in inference depth starting in February.
More detailed findings indicated that Claude began to get stuck in reasoning loops and showed a clear tendency to choose “the simplest fix” rather than the correct one.
BridgeMind’s BridgeBench tests also reported a drop in Opus 4.6’s accuracy from 83.3% to 68.3%, falling from 2nd to 10th place.
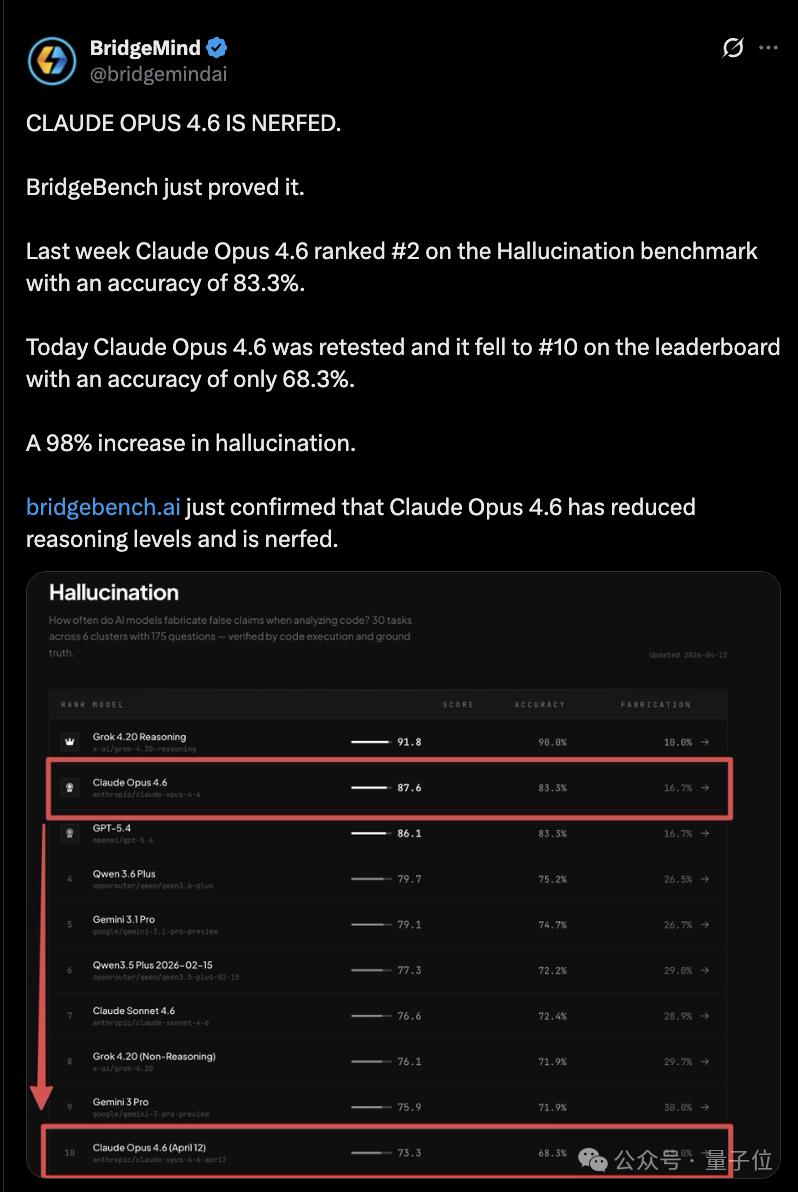
Although researchers later criticized the methodology as flawed due to differing task counts, the narrative of “Claude has become less intelligent” has spread widely.
Users even coined a new term, AI shrinkflation, indicating that for the same price, they received a diluted product.
In other words, users ended up with Anthropic’s “children’s meal.”
Despite this, Claude was previously unbeatable, and many users continued using it despite their complaints.
Once GPT-5.5 was released, Anthropic could no longer sit idle and published a postmortem on their blog, breaking down the past two months of performance issues into three distinct problems:
Secretly downgraded inference level.
On March 4, Claude Code’s default inference was changed from high to medium due to high latency in high mode. However, the interface still displayed “high.” Users believed they were using the full version, but in reality, they received a downgraded product. It took over a month to revert this change.
Deteriorating performance over conversations.
On March 26, a caching optimization was implemented intended to clear old thought records after an hour of inactivity. However, a bug caused this to execute every round, leading Claude to forget the context of conversations. Symptoms included forgetfulness, repetition, and erratic tool calls.
Due to the repeated clearing of thought records, each request resulted in cache misses, causing token consumption to soar. It took 15 days to fix this issue.
A prompt limitation that degraded output quality.
On April 16, a system prompt was added stating that text between tool calls should not exceed 25 words, and final responses should not exceed 100 words.
Opus 4.6 and 4.7 both saw a 3% drop in performance, and four days later, this change was rolled back.
These three issues affected different user groups at various times. The cumulative effect was a gradual and uneven decline in the overall performance of Claude Code, leaving users confused about the underlying problems.
On Twitter, ClaudeDevs summarized the situation, and Claude’s creator Boris Cherny personally responded, indicating that the bugs in Opus 4.7 were also being addressed.
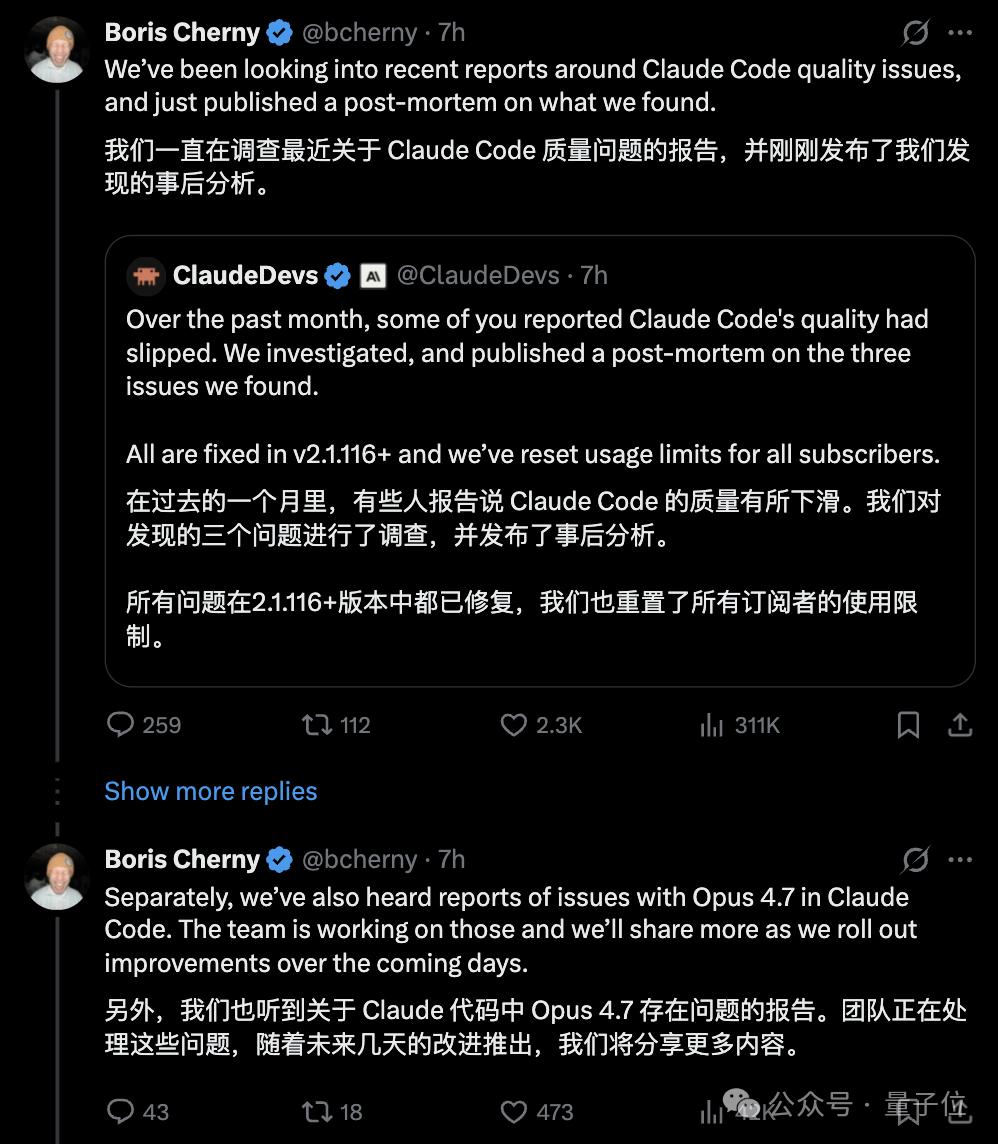
However, merely acknowledging bugs does not explain everything that has transpired over the past two months.
Anthropic’s Missteps in April
Looking at the timeline, April was a month of continuous self-inflicted wounds for Anthropic.
On April 4, Anthropic banned third-party agentic tools like OpenClaw from running through Pro/Max subscriptions, requiring users to switch to API-based token payments.
On April 21, the official pricing page quietly removed Claude Code from the Pro plan, changing support documentation from “Pro or Max plan” to “only Max plan.”
After being caught by users, Head of Growth Amol Avasare claimed this was just an A/B test for 2% of new users. However, the public page was updated site-wide, leading to a complete mismatch in statements. Hours later, they had to roll back the changes.
When adding it all up, the costs become apparent. Pro users pay $20/month, totaling $240 annually. To continue using Claude Code, they must upgrade to Max at $100/month, starting at $1,200 annually—five times the cost. Max 20x is $2,400, or ten times the cost. There are no transitional tiers.
Note that these figures are in USD.
On April 23, the postmortem was released, with compensation being the reset of usage quotas.
Some users pointed out that the usage quotas had already been reset last week with the release of Opus 4.7, so this “compensation” was essentially a normal cycle reset.
When these three issues are considered together, it suggests that the situation is not merely about bugs but rather a full-blown cost anxiety crisis.
User Reactions
In light of all this, user reactions to Claude have become polarized.
Some find it understandable that bugs occur and appreciate the transparency of the postmortem. Boris’s detailed responses on Hacker News are seen as better than what most companies provide.

However, many are calculating the costs.
During the past two months, there has been a complete silence from official channels.
Only a few employees sporadically responded to users on X, and they were criticized for their “random timing and random replies,” which lacked coherence.

Some users even questioned the true motives behind the “caching optimization.” The timing of clearing thought records coincided with cache expiration, leading some to believe it was not about reducing latency but rather about cutting costs.
During the same period, Anthropic conducted A/B tests on a small number of Pro users, quietly providing different product configurations, further eroding trust.

The compensation measure of resetting usage quotas was met with skepticism, as it had already occurred the previous week.
BridgeMind’s BridgeBench tests also revealed that Opus 4.6’s accuracy plummeted from 83.3% to 68.3%, dropping from 2nd to 10th place.
Although researchers later criticized the methodology, the narrative of “Claude has become less intelligent” has taken hold.
As one user aptly stated, one should not put all their eggs in one model company’s basket.

One More Thing
An interesting phenomenon in the Hacker News comment section is that many users are sharing their “migration experiences.”
Some mentioned that they subconsciously switched to Codex back in February, only realizing later that it was likely due to Claude’s decline.

Others noted that GPT-5.4 is already better than Opus 4.6.

Some are using MiniMax as a supplement, paying $40 for 4,500 messages over a 5-hour period while being able to see the complete thought process.

Half a year ago, the consensus was to use Claude for coding.
Now, Codex has 4 million active users, and GPT-5.5 is designed for coding and computational tasks, with even OpenAI representatives stating that this model can serve as a “chief of staff.”
Claude has not just declined; others have improved while it faltered at a critical time.
The window for Anthropic to fix bugs and rebuild trust has narrowed significantly compared to two months ago.
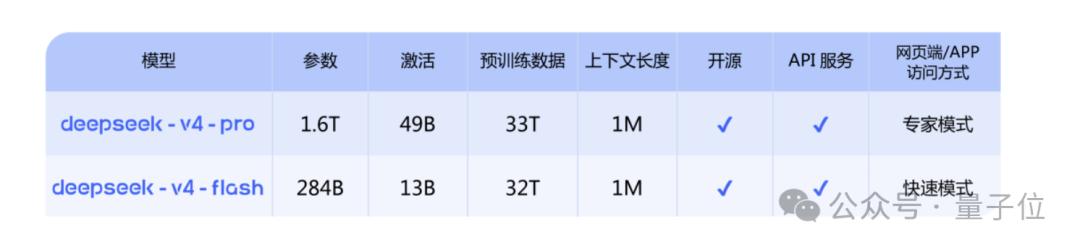
With GPT-5.5 already released, DeepSeek V4 is evidently ready to go.
Gemini, we are waiting for you!
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.