The Emergence of Skill after MCP
AI tools are undergoing a paradigm shift from MCP (Model Context Protocol) to Skill. While MCP addressed the standardization of AI connections to external tools, it led to context disasters. Skill, through progressive disclosure and preset scripts, fundamentally restructured the cognitive logic of AI. This article deeply analyzes the design philosophies and technical differences between the two architectures, revealing the key transition in AI engineering from ‘capable’ to ‘capable of doing well’ and how product managers can redefine AI’s operational methods in this transformation.

Many who have experimented with AI tools have recently experienced a subtle confusion. After finally understanding MCP and configuring Claude Desktop with several popular MCP servers, they were excited to start working, only to find that the AI occasionally selected the wrong tools and sometimes froze, with response times frustratingly slow.
Before they could troubleshoot the configuration issues, the developer community had already shifted focus: “Skill has arrived!” “Skill is the future!” “MCP will be obsolete!”
Staring at the screen, they might be left wondering: Wasn’t MCP touted as the ultimate solution? What new problems does Skill solve? Do we need to rebuild the infrastructure we just set up?
To clarify the relationship between these two, we must first step back from the code and discuss the real pain points in the evolution of AI tools.
The Birth of MCP: Ending the “Charging Cable Disaster” for AI Tools
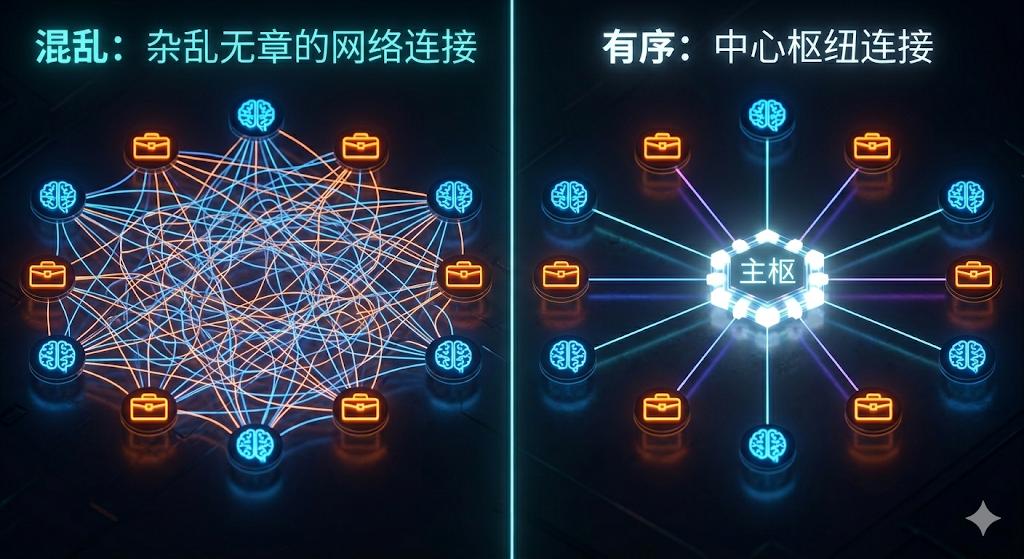
To understand why MCP was elevated to such heights, we must return to the chaotic technological period before 2024. At that time, the connection methods for AI tools were a complete disaster. Each AI application needed to write a separate integration logic to call external tools. Want an agent to read a GitHub repository? Write an interface. Want ChatGPT to query a local database? Write another one. Want Cursor to send a Slack message? Keep writing.
This issue is mathematically described in engineering as the “M×N problem.” M AI applications need to connect to N external tools, theoretically requiring M multiplied by N custom integrations. Ten applications connecting to twenty tools means 200 sets of reinvented wheels. Companies were wasting significant energy on uncreative “interface adaptation.”
Worse still, these integrations had no standards. The entire ecosystem resembled a chaotic mess of charging cables: Apple used Lightning, Android used Micro USB, and a trip out could mean carrying five or six cables, not knowing if any would fit.
Until November 2024, when Anthropic did something comparable to introducing the “USB-C unified charging standard”—they open-sourced MCP.
The core idea of MCP is elegant: define a universal standard protocol that allows any AI to connect to any external tool plug-and-play. With MCP, the M×N combinations turned into linear growth of M+N. Ten AI applications and twenty tools only require 30 sets of MCP implementations.
This was a true “standardization revolution” in the AI engineering community. SDK downloads exceeded ten million per month, and tens of thousands of related repositories emerged on GitHub. Everyone celebrated the victory of interoperability. However, amidst the excitement, a critical hidden danger was quietly accumulating.
The Hidden Cost of MCP: Silently Consuming AI’s “Brain Capacity”
MCP perfectly solved the connection problem but brought a rarely analyzed side effect: context disaster.
How does AI “understand” tools? In MCP’s design mechanism, whenever a server connects to AI, it must shove the complete definition of all its tools—including names, descriptions, parameter lists, and usage examples—into the AI’s context window all at once.
A standard tool definition requires about 500 to 800 tokens. An MCP server typically bundles 10 to 20 tools. This means that just for “self-introduction,” a server can consume 5,000 to 16,000 tokens.
In real scenarios, the data is even more alarming. Developers configuring seven MCP servers found that before even entering the first prompt, the context was already using 67,000 tokens, directly consuming one-third of the entire AI context window. In extreme cases, it reached 82,000 tokens.
This leads to two serious consequences. First, the costs are exorbitant. If you ask AI, “How’s the weather today?” even if the answer only requires a few tokens, the tens of thousands of tokens for tool definitions still incur charges.
Second, there’s a degradation of intelligence. AI working in an extremely crowded context is like a person trying to solve calculus in a noisy market; the probability of selecting the wrong tool or passing the wrong parameters increases exponentially. This is why many feel that after connecting multiple MCPs, AI becomes “dumber.”
Although Anthropic later introduced the Tool Search feature, which reduced context consumption by 85% through dynamic retrieval, it remains a patch. The underlying assumption of MCP is still to “lay out all tools for AI to choose from.” Moreover, the intermediate return results from tool calls in complex tasks continue to consume large amounts of context.
MCP is naturally more suitable for developers to build ecosystems, but the user experience is not perfect. This is where Skill comes in.
The Essence of Skill: Not a Replacement, but a Different Philosophy
To anchor the positioning of the two in one sentence: MCP is the USB protocol, defining what AI can connect to; Skill is the application program, defining how AI should intelligently use these capabilities.
MCP addresses the physical problem of “external connections,” while Skill addresses the logical problem of “internal cognition.”
From the start, Skill adopted a radically different design philosophy called Progressive Disclosure.
Imagine you are at a massive library searching for information. MCP’s approach is like the librarian pushing hundreds of bookshelves in front of you, saying, “All the books are here, find them yourself.” The information is indeed complete, but you are instantly overwhelmed.
Skill’s approach is to first hand you a very minimal directory. After you look it over and say, “I need the content of chapter three,” the librarian retrieves that specific book for you. You only handle the most necessary information at any given time.

Technically, Skill divides capability information into three layers:
- Metadata Layer: Loaded at startup, consuming only about 100 tokens, informing AI, “I have this capability.”
- Core Instruction Layer: Loaded only when AI decides to execute a task, containing specific operational steps.
- Reference Material Layer: Pulled on-demand when encountering specific difficulties during execution, even if it includes hundreds of pages of API documentation, it does not occupy context unless triggered.
In addition to extremely restrained context management, Skill has a true game-changer: executable scripts.
A standard Skill package typically includes pre-written Python, Bash, or JavaScript scripts. When AI needs to handle complex logic (like cleaning a PDF dataset), it doesn’t need to write code itself or load the script source code into context; it simply calls the script, passes in the file path, and receives the final output.
Script execution = zero context code loading + absolutely certain execution results.
Progressive disclosure solves the problem of “too much knowledge leading to insufficient AI brain capacity,” while script execution addresses the issue of “too cumbersome interactions leading to AI decision-making errors.”
Practical Comparison: How the 100x Context Consumption Difference Arises
Theoretical discussions are no match for real data comparisons. Suppose we want to complete a task: automatically publish a Markdown-formatted article to X (formerly Twitter) in the long-form section.
Option 1: Using Playwright MCP
This is the most conventional approach. AI calls Playwright to control the browser, step by step opening pages, clicking input boxes, pasting text, uploading images, and clicking publish.
In this process, the Playwright MCP tool definition consumes about 10,000 tokens. More alarmingly, with each click, MCP needs to return the current accessibility tree snapshot to AI, allowing it to “see” the changes on the page. A complex webpage snapshot can easily consume several thousand tokens. Completing a single publish requires AI to make seven or eight interactive decisions.
Final consumption: over 50,000 tokens.
Option 2: Using Skill + CDP Script
We encapsulate this process into a Skill. The Skill’s description file is extremely brief, with the core logic written in a low-level script utilizing Chrome CDP to operate the browser.
AI doesn’t need to know how to click buttons; it only needs to do one thing: call this Skill script and pass in the path of the Markdown file. The rest of the browser automation is silently handled by the script in the background.
Final consumption: a few hundred tokens.
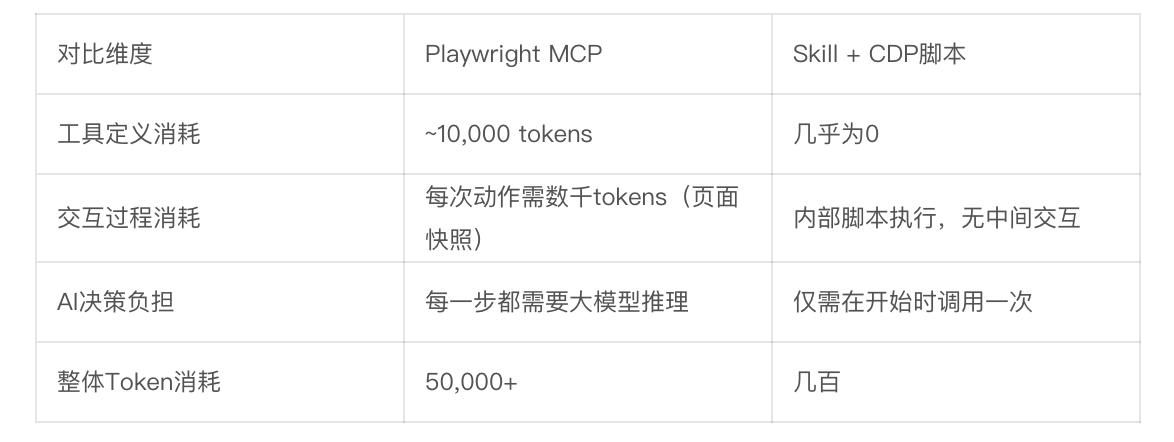
The consumption difference of over 100 times reveals a core insight: MCP forces AI to act like a marionette, requiring brain commands for every step; whereas Skill encapsulates complex processes into an automated black box, allowing AI to act as the commanding officer.
MCP and Skill: An Excellent Pair of External Sensory and Internal Intelligence
After reading this, you might feel an urge: since Skill is so powerful, should we uninstall MCP altogether?
Absolutely not. Pitting them against each other forces two different dimensions of tools into the same arena. They are naturally complementary partners.
MCP is the sensory and motor functions of AI. It connects to the external real world. Checking real-time stock prices, reading corporate private databases, and calling third-party SaaS interfaces all depend on standardized network communication, which is MCP’s stronghold. It targets the vast internet ecosystem.
Skill is the brain circuits and operational manual of AI. It consolidates internal expertise and standard operating procedures. Efficient handling of local files, specific job workflow logic, and automation scripts that do not need to be externally exposed are best encapsulated with Skill. It acts like an internal business flow guide, called on-demand, precise, and efficient.
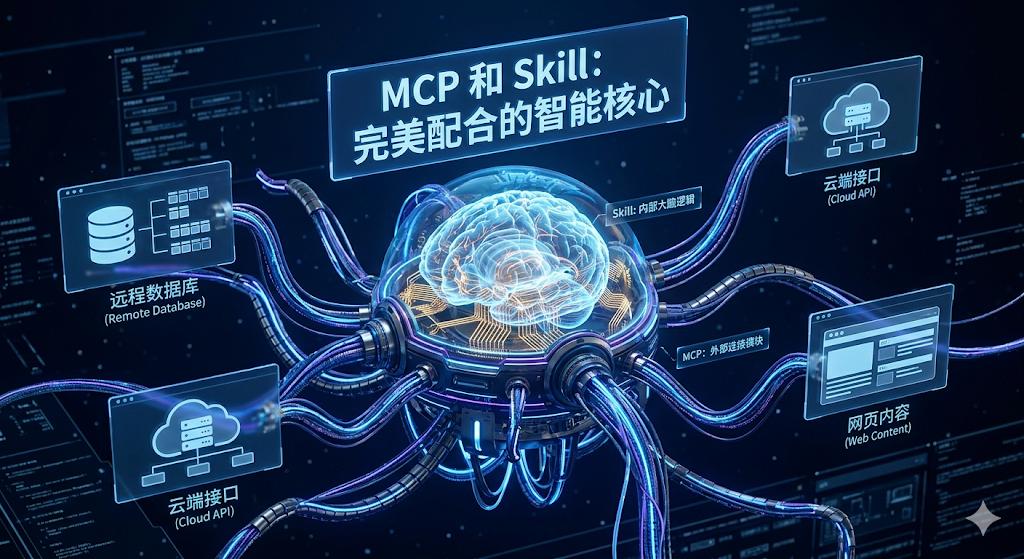
A truly mature agent architecture must combine both: using Skill to define “how to logically process tasks of this type” while utilizing MCP to “fetch the real-time data needed from the outside world.” Without either, AI is incomplete.
Product Perspective: Who Defines AI’s Working Methods?
Stepping out of the engineer’s mindset and looking from a product design perspective, the alternating evolution of MCP and Skill releases an essential signal: the core of AI engineering is shifting from “making AI capable” to “making AI precise and efficient.”
In this transition, a new product proposition emerges: as AI’s attention becomes a scarce resource, who decides what it should prioritize remembering and what to ignore?
In the past, we relied on writing prompts to solve this issue, but prompts are fragile and difficult to manage structurally. Now, Skill truly encapsulates business logic into reusable, version-controlled digital assets.
This means product managers are no longer just writing PRDs (Product Requirement Documents) for developers but can directly write and maintain Skill packages. You can clearly describe in Markdown the “five judgment steps AI should follow when processing user refunds” and assign it as a Skill to the agent.
MCP paves the highway for AI to the world, while Skill draws an extremely detailed navigation map for AI. Understanding and mastering how to allocate knowledge and plan workflows for AI is becoming the core capability barrier for the next generation of product innovators.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.